■ HumanMessagePromptTemplate 클래스의 from_template 정적 메소드를 사용해 HumanMessagePromptTemplate 객체를 만드는 방법을 보여준다. ▶ main.py
|
|
from langchain_core.prompts import HumanMessagePromptTemplate humanTemplateString = "{재료}" humanMessagePromptTemplate = HumanMessagePromptTemplate.from_template(humanTemplateString) |
▶ requirements.txt
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
aiohappyeyeballs==2.4.0 aiohttp==3.10.5 aiosignal==1.3.1 annotated-types==0.7.0 anyio==4.4.0 attrs==24.2.0 certifi==2024.8.30 charset-normalizer==3.3.2 frozenlist==1.4.1 greenlet==3.1.0 h11==0.14.0 httpcore==1.0.5 httpx==0.27.2 idna==3.8 jsonpatch==1.33 jsonpointer==3.0.0 langchain==0.2.16 langchain-core==0.2.39 langchain-text-splitters==0.2.4 langsmith==0.1.117 multidict==6.1.0 numpy==1.26.4 orjson==3.10.7 packaging==24.1 pydantic==2.9.1 pydantic_core==2.23.3 PyYAML==6.0.2 requests==2.32.3 sniffio==1.3.1 SQLAlchemy==2.0.34 tenacity==8.5.0 typing_extensions==4.12.2 urllib3==2.2.2 yarl==1.11.1 |
※ pip install langchain
더 읽기
■ SystemMessagePromptTemplate 클래스의 from_template 정적 메소드를 사용해 SystemMessagePromptTemplate 객체를 만드는 방법을 보여준다. ▶ main.py
|
|
from langchain_core.prompts import SystemMessagePromptTemplate systemTemplateString = """ 당신은 요리사입니다. 제가 가진 재료들을 갖고 만들 수 있는 요리를 추천하고, 그 요리의 레시피를 추천해주시기 바랍니다. 제가 가진 재료는 아래와 같습니다. <재료> {재료} """ systemMessagePromptTemplate = SystemMessagePromptTemplate.from_template(systemTemplateString) |
▶ requirements.txt
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
aiohappyeyeballs==2.4.0 aiohttp==3.10.5 aiosignal==1.3.1 annotated-types==0.7.0 anyio==4.4.0 attrs==24.2.0 certifi==2024.8.30 charset-normalizer==3.3.2 frozenlist==1.4.1 greenlet==3.1.0 h11==0.14.0 httpcore==1.0.5 httpx==0.27.2 idna==3.8 jsonpatch==1.33 jsonpointer==3.0.0 langchain==0.2.16 langchain-core==0.2.39 langchain-text-splitters==0.2.4 langsmith==0.1.117 multidict==6.1.0 numpy==1.26.4 orjson==3.10.7 packaging==24.1 pydantic==2.9.1 pydantic_core==2.23.3 PyYAML==6.0.2 requests==2.32.3 sniffio==1.3.1 SQLAlchemy==2.0.34 tenacity==8.5.0 typing_extensions==4.12.2 urllib3==2.2.2 yarl==1.11.1 |
※ pip install langchain
더 읽기
■ PromptTemplate 클래스의 생성자에서 input_variables/template 인자를 사용해 PromptTemplate 객체를 만드는 방법을 보여준다. ※ OPENAI_API_KEY 환경 변수 값은 .env 파일에 정의한다. ▶ main.py
더 읽기
■ ChatPromptTemplate 클래스의 format_prompt 메소드를 사용해 ChatPromptValue 객체를 만드는 방법을 보여준다. ▶ main.py
|
|
from langchain_core.prompts import ChatPromptTemplate chatPromptTemplate = ChatPromptTemplate.from_template("tell me a joke about {subject}") chatPromptValue = chatPromptTemplate.format_prompt(subject = "soccer") humanMessage = chatPromptValue.messages[0] print(humanMessage.content) |
▶ requirements.txt
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
aiohappyeyeballs==2.4.0 aiohttp==3.10.5 aiosignal==1.3.1 annotated-types==0.7.0 anyio==4.4.0 attrs==24.2.0 certifi==2024.8.30 charset-normalizer==3.3.2 frozenlist==1.4.1 greenlet==3.1.0 h11==0.14.0 httpcore==1.0.5 httpx==0.27.2 idna==3.8 jsonpatch==1.33 jsonpointer==3.0.0 langchain==0.2.16 langchain-core==0.2.39 langchain-text-splitters==0.2.4 langsmith==0.1.117 multidict==6.1.0 numpy==1.26.4 orjson==3.10.7 packaging==24.1 pydantic==2.9.1 pydantic_core==2.23.3 PyYAML==6.0.2 requests==2.32.3 sniffio==1.3.1 SQLAlchemy==2.0.34 tenacity==8.5.0 typing_extensions==4.12.2 urllib3==2.2.2 yarl==1.11.1 |
※ pip install langchain 명령을
더 읽기
■ ChatPromptTemplate 클래스의 from_template 정적 메소드를 사용해 ChatPromptTemplate 객체를 만드는 방법을 보여준다. ▶ main.py
|
|
from langchain_core.prompts import ChatPromptTemplate chatPromptTemplate = ChatPromptTemplate.from_template("tell me a joke about {subject}") |
▶ requirements.txt
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
aiohappyeyeballs==2.4.0 aiohttp==3.10.5 aiosignal==1.3.1 annotated-types==0.7.0 anyio==4.4.0 attrs==24.2.0 certifi==2024.8.30 charset-normalizer==3.3.2 frozenlist==1.4.1 greenlet==3.1.0 h11==0.14.0 httpcore==1.0.5 httpx==0.27.2 idna==3.8 jsonpatch==1.33 jsonpointer==3.0.0 langchain==0.2.16 langchain-core==0.2.39 langchain-text-splitters==0.2.4 langsmith==0.1.117 multidict==6.1.0 numpy==1.26.4 orjson==3.10.7 packaging==24.1 pydantic==2.9.1 pydantic_core==2.23.3 PyYAML==6.0.2 requests==2.32.3 sniffio==1.3.1 SQLAlchemy==2.0.34 tenacity==8.5.0 typing_extensions==4.12.2 urllib3==2.2.2 yarl==1.11.1 |
※ pip install langchain
더 읽기
■ PromptTemplate 클래스의 format_prompt 메소드를 사용해 StringPromptValue 객체를 만드는 방법을 보여준다. ▶ main.py
|
|
from langchain_core.prompts import PromptTemplate promptTemplate = PromptTemplate.from_template("tell me a joke about {subject}") stringPromptValue = promptTemplate.format_prompt(subject = "soccer") print(stringPromptValue.text) |
▶ requirements.txt
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
aiohappyeyeballs==2.4.0 aiohttp==3.10.5 aiosignal==1.3.1 annotated-types==0.7.0 anyio==4.4.0 attrs==24.2.0 certifi==2024.8.30 charset-normalizer==3.3.2 frozenlist==1.4.1 greenlet==3.1.0 h11==0.14.0 httpcore==1.0.5 httpx==0.27.2 idna==3.8 jsonpatch==1.33 jsonpointer==3.0.0 langchain==0.2.16 langchain-core==0.2.39 langchain-text-splitters==0.2.4 langsmith==0.1.117 multidict==6.1.0 numpy==1.26.4 orjson==3.10.7 packaging==24.1 pydantic==2.9.1 pydantic_core==2.23.3 PyYAML==6.0.2 requests==2.32.3 sniffio==1.3.1 SQLAlchemy==2.0.34 tenacity==8.5.0 typing_extensions==4.12.2 urllib3==2.2.2 yarl==1.11.1 |
※ pip install langchain 명령을
더 읽기
■ PromptTemplate 클래스의 from_template 정적 메소드를 사용해 PromptTemplate 객체를 만드는 방법을 보여준다. ▶ main.py
|
|
from langchain_core.prompts import PromptTemplate promptTemplate = PromptTemplate.from_template("tell me a joke about {subject}") |
▶ requirements.txt
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
aiohappyeyeballs==2.4.0 aiohttp==3.10.5 aiosignal==1.3.1 annotated-types==0.7.0 anyio==4.4.0 attrs==24.2.0 certifi==2024.8.30 charset-normalizer==3.3.2 frozenlist==1.4.1 greenlet==3.1.0 h11==0.14.0 httpcore==1.0.5 httpx==0.27.2 idna==3.8 jsonpatch==1.33 jsonpointer==3.0.0 langchain==0.2.16 langchain-core==0.2.39 langchain-text-splitters==0.2.4 langsmith==0.1.117 multidict==6.1.0 numpy==1.26.4 orjson==3.10.7 packaging==24.1 pydantic==2.9.1 pydantic_core==2.23.3 PyYAML==6.0.2 requests==2.32.3 sniffio==1.3.1 SQLAlchemy==2.0.34 tenacity==8.5.0 typing_extensions==4.12.2 urllib3==2.2.2 yarl==1.11.1 |
※ pip install langchain
더 읽기
■ ChatOpenAI 클래스의 invoke 메소드에서 SystemMessage/HumanMessage 객체 리스를 사용하는 방법을 보여준다. ※ OPENAI_API_KEY 환경 변수 값은 .env 파일에 정의한다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
from dotenv import load_dotenv from langchain_openai import ChatOpenAI from langchain_core.messages import SystemMessage from langchain_core.messages import HumanMessage load_dotenv() chatOpenAI = ChatOpenAI(model_name = "gpt-4o-mini", temperature = 0) messageList = [ SystemMessage(content = "You are a helpful assistant that translaes English to Korean."), HumanMessage(content = "I love langchain.") ] responseAIMessage = chatOpenAI.invoke(messageList) print(responseAIMessage.content) |
더 읽기
■ ChatOpenAI 클래스의 생성자에서 temperature 인자를 사용해 답변 일관성/창의성 정도를 설정하는 방법을 보여준다. ※ OPENAI_API_KEY 환경 변수 값은 .env 파일에 정의한다. ▶
더 읽기
■ ChatOpenAI 클래스의 생성자에서 model_name 인자를 사용해 채팅 모델명을 설정하는 방법을 보여준다. ※ OPENAI_API_KEY 환경 변수 값은 .env 파일에 정의한다. ▶ main.py
더 읽기
■ OpenAI 클래스의 생성자에서 model_name 인자를 사용해 모델명을 설정하는 방법을 보여준다. ※ OPENAI_API_KEY 환경 변수 값은 .env 파일에 정의한다. ▶ main.py
|
|
from dotenv import load_dotenv from langchain_openai import OpenAI load_dotenv() openAI = OpenAI(model_name = "gpt-3.5-turbo-instruct") # 대화 기능에 특화되어 있지 않다. responseString = openAI.invoke("why python is the most popular langhages? answer in Korean.") print(responseString) |
더 읽기
■ ContextualCompressionRetriever 클래스에서 DocumentCompressorPipeline 객체를 사용해 컨텍스트 압축 검색하는 방법을 보여준다. ※ OPENAI_API_KEY 환경 변수 값은 .env 파일에 정의한다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
from dotenv import load_dotenv from langchain_community.document_loaders import TextLoader from langchain_text_splitters import CharacterTextSplitter from langchain_openai import OpenAIEmbeddings from langchain_community.vectorstores import FAISS from langchain_community.document_transformers import EmbeddingsRedundantFilter from langchain.retrievers.document_compressors import EmbeddingsFilter from langchain.retrievers.document_compressors import DocumentCompressorPipeline from langchain.retrievers import ContextualCompressionRetriever load_dotenv() def printDocumentList(documentList): print( f"\n{'-' * 100}\n".join( [f"Document {i + 1} :\n\n" + document.page_content for i, document in enumerate(documentList)] ) ) textLoader = TextLoader("state_of_the_union.txt") documentList = textLoader.load() characterTextSplitter1 = CharacterTextSplitter(chunk_size = 1000, chunk_overlap = 0) splitDocumentList = characterTextSplitter1.split_documents(documentList) openAIEmbeddings = OpenAIEmbeddings() faiss = FAISS.from_documents(splitDocumentList, openAIEmbeddings) vectorStoreRetriever = faiss.as_retriever() characterTextSplitter2 = CharacterTextSplitter(chunk_size = 300, chunk_overlap = 0, separator = ". ") embeddingsRedundantFilter = EmbeddingsRedundantFilter(embeddings = openAIEmbeddings) embeddingsFilter = EmbeddingsFilter(embeddings = openAIEmbeddings, similarity_threshold = 0.76) documentCompressorPipeline = DocumentCompressorPipeline(transformers = [characterTextSplitter2, embeddingsRedundantFilter, embeddingsFilter]) contextualCompressionRetriever = ContextualCompressionRetriever(base_compressor = documentCompressorPipeline, base_retriever = vectorStoreRetriever) resultDocumentList = contextualCompressionRetriever.invoke("What did the president say about Ketanji Jackson Brown") printDocumentList(resultDocumentList) |
더 읽기
■ DocumentCompressorPipeline 클래스의 생성자에서 transformers 인자를 사용해 DocumentCompressorPipeline 객체를 만드는 방법을 보여준다. ▶ 예제 코드 (PY)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
from langchain_openai import OpenAIEmbeddings from langchain_text_splitters import CharacterTextSplitter from langchain_community.document_transformers import EmbeddingsRedundantFilter from langchain.retrievers.document_compressors import EmbeddingsFilter from langchain.retrievers.document_compressors import DocumentCompressorPipeline openAIEmbeddings = OpenAIEmbeddings() characterTextSplitter = CharacterTextSplitter(chunk_size = 300, chunk_overlap = 0, separator = ". ") embeddingsRedundantFilter = EmbeddingsRedundantFilter(embeddings = openAIEmbeddings) embeddingsFilter = EmbeddingsFilter(embeddings = openAIEmbeddings, similarity_threshold = 0.76) documentCompressorPipeline = DocumentCompressorPipeline(transformers = [characterTextSplitter, embeddingsRedundantFilter, embeddingsFilter]) |
■ EmbeddingsRedundantFilter 클래스의 생성자에서 embeddings 인자를 사용해 EmbeddingsRedundantFilter 객체를 만드는 방법을 보여준다. ▶ 예제 코드 (PY)
|
|
from langchain_openai import OpenAIEmbeddings from langchain_community.document_transformers import EmbeddingsRedundantFilter openAIEmbeddings = OpenAIEmbeddings() embeddingsRedundantFilter = EmbeddingsRedundantFilter(embeddings = openAIEmbeddings) |
■ EmbeddingsFilter 클래스의 생성자에서 embeddings/similarity_threshold 인자를 사용해 EmbeddingsFilter 객체를 만드는 방법을 보여준다. ▶ 예제 코드 (PY)
|
|
from langchain_openai import OpenAIEmbeddings from langchain.retrievers.document_compressors import EmbeddingsFilter openAIEmbeddings = OpenAIEmbeddings() embeddingsFilter = EmbeddingsFilter(embeddings = openAIEmbeddings, similarity_threshold = 0.76) |
■ ContextualCompressionRetriever 클래스에서 EmbeddingsFilter 객체를 사용해 컨텍스트 압축 검색하는 방법을 보여준다. ※ OPENAI_API_KEY 환경 변수 값은 .env 파일에 정의한다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
from dotenv import load_dotenv from langchain_community.document_loaders import TextLoader from langchain_text_splitters import CharacterTextSplitter from langchain_openai import OpenAIEmbeddings from langchain_community.vectorstores import FAISS from langchain.retrievers.document_compressors import EmbeddingsFilter from langchain.retrievers import ContextualCompressionRetriever load_dotenv() def printDocumentList(documentList): print( f"\n{'-' * 100}\n".join( [f"Document {i + 1} :\n\n" + document.page_content for i, document in enumerate(documentList)] ) ) textLoader = TextLoader("state_of_the_union.txt") documentList = textLoader.load() characterTextSplitter = CharacterTextSplitter(chunk_size = 1000, chunk_overlap = 0) splitDocumentList = characterTextSplitter.split_documents(documentList) openAIEmbeddings = OpenAIEmbeddings() faiss = FAISS.from_documents(splitDocumentList, openAIEmbeddings) vectorStoreRetriever = faiss.as_retriever() embeddingsFilter = EmbeddingsFilter(embeddings = openAIEmbeddings, similarity_threshold = 0.76) contextualCompressionRetriever = ContextualCompressionRetriever(base_compressor = embeddingsFilter, base_retriever = vectorStoreRetriever) resultDocumentList = contextualCompressionRetriever.invoke("What did the president say about Ketanji Jackson Brown") printDocumentList(resultDocumentList) |
더 읽기
■ FAISS 클래스의 as_retriever 메소드에서 search_kwargs 인자를 사용해 벡터 스토어 검색기를 구하는 방법올 보여준다. ※ OPENAI_API_KEY 환경 변수 값은 .env 파일에 정의한다.
더 읽기
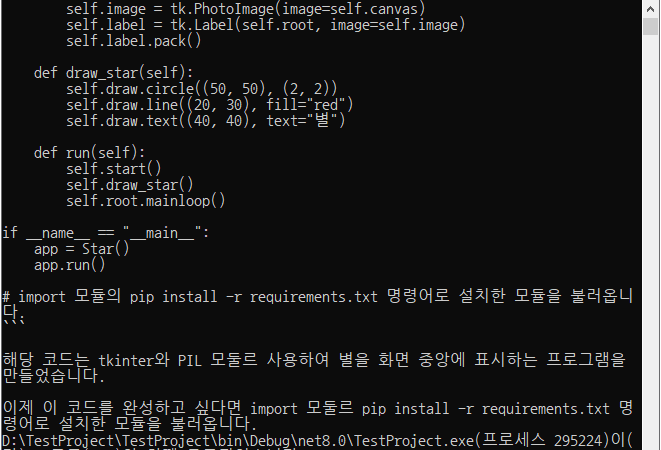
■ HttpClient 클래스를 사용해 Ollama 연동 파이썬 LLM 서버와 통신하는 방법을 보여준다. ▶ AdditionalKeywordArgument.cs
|
|
namespace TestProject; /// <summary> /// 부가적 키워드 인자 /// </summary> public class AdditionalKeywordArgument { } |
▶ AIMessageChunk.cs
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 |
using Newtonsoft.Json; namespace TestProject; /// <summary> /// AI 메시지 청크 /// </summary> public class AIMessageChunk { //////////////////////////////////////////////////////////////////////////////////////////////////// Property ////////////////////////////////////////////////////////////////////////////////////////// Public #region 컨텐트 - Content /// <summary> /// 컨텐트 /// </summary> [JsonProperty("content")] public string Content { get; set; } #endregion #region 부가적 키워드 인자 - AdditionalKeywordArgument /// <summary> /// 부가적 키워드 인자 /// </summary> [JsonProperty("additional_kwargs")] public AdditionalKeywordArgument AdditionalKeywordArgument { get; set; } #endregion #region 응답 메타 데이터 - ResponseMetadata /// <summary> /// 응답 메타 데이터 /// </summary> [JsonProperty("response_metadata")] public ResponseMetadata ResponseMetadata { get; set; } #endregion #region 타입 - Type /// <summary> /// 타입 /// </summary> [JsonProperty("type")] public string Type { get; set; } #endregion #region 명칭 - Name /// <summary> /// 명칭 /// </summary> [JsonProperty("name")] public string Name { get; set; } #endregion #region ID - ID /// <summary> /// ID /// </summary> [JsonProperty("id")] public string ID { get; set; } #endregion #region 예제 여부 - Example /// <summary> /// 예제 여부 /// </summary> [JsonProperty("example")] public bool Example { get; set; } #endregion #region 도구 호출 리스트 - ToolCallList /// <summary> /// 도구 호출 리스트 /// </summary> [JsonProperty("tool_calls")] public ToolCallList ToolCallList { get; set; } #endregion #region 무효 도구 호출 리스트 - InvalidToolCallList /// <summary> /// 무효 도구 호출 리스트 /// </summary> [JsonProperty("invalid_tool_calls")] public InvalidToolCallList InvalidToolCallList { get; set; } #endregion #region 사용 메타 데이터 - UsageMetadata /// <summary> /// 사용 메타 데이터 /// </summary> [JsonProperty("usage_metadata")] public UsageMetadata UsageMetadata { get; set; } #endregion #region 도구 호출 청크 리스트 - ToolCallChunkList /// <summary> /// 도구 호출 청크 리스트 /// </summary> [JsonProperty("tool_call_chunks")] public ToolCallChunkList ToolCallChunkList { get; set; } #endregion } |
▶ InvalidToolCallList.cs
|
|
using System.Collections.Generic; namespace TestProject; /// <summary> /// 무효 도구 호출 리스트 /// </summary> public class InvalidToolCallList : List<object> { } |
▶
더 읽기
■ 라마 3.1 한국어 모델과 채팅하는 서버/클라이언트 프로그램을 만드는 방법을 보여준다. ※ Ollama 설치/실행과 llama3.1:8b-instruct-q2_K 모델이 다운로드 되어 있어야 한다. ▶ server.py
더 읽기
■ 라마 3.1 한국어 모델과 채팅하는 서버/클라이언트 프로그램을 만드는 방법을 보여준다. ※ Ollama 설치/실행과 llama3.1:8b-instruct-q2_K 모델이 다운로드 되어 있어야 한다. ▶ server.py
더 읽기
■ ChatOllama 클래스를 사용해 ollama에서 gemma2 모델 챗봇을 만드는 방법을 보여준다. ※ Ollama 설치와 gemma2:2b 모델이 다운로드 되어 있어야 한다. ▶ main.py
더 읽기
■ ChatOllama 클래스를 사용해 ollama에서 gemma2 모델 채팅 프로그램을 만드는 방법을 보여준다. ※ Ollama 설치와 gemma2:2b 모델이 다운로드 되어 있어야 한다. ▶
더 읽기
■ ollama 명령의 create 옵션을 사용해 .gguf 파일에서 모델을 생성하는 방법을 보여준다. 1. 명령 프롬프트를 실행한다. 2. 아래 스크립트를 실행한다. ▶ 실행
더 읽기
■ AgentExecutor 클래스를 사용해 크롬 브라우저 웹 주소를 구하거나 윈도우즈 메모장을 실행하는 방법을 보여준다. ※ Ollama 설치와 benedict/linkbricks-llama3.1-korean:8b 모델이 다운로드 되어 있어야
더 읽기
■ ConversationBufferMemory 클래스의 생성자를 사용해 객체를 만드는 방법을 보여준다. ▶ 예제 코드 (PY)
|
|
from langchain.memory import ConversationBufferMemory conversationBufferMemory = ConversationBufferMemory(memory_key = "chat_history", return_messages = True) |