[PYTHON/TRANSFORMERS] transformers 패키지 설치하기
■ transformers 패키지를 설치하는 방법을 보여준다. 1. 명령 프롬프트를 실행한다. 2. 명령 프롬프트에서 아래 명령을 실행한다. ▶ 실행 명령
|
1 2 3 |
pip install transformers |
■ transformers 패키지를 설치하는 방법을 보여준다. 1. 명령 프롬프트를 실행한다. 2. 명령 프롬프트에서 아래 명령을 실행한다. ▶ 실행 명령
|
1 2 3 |
pip install transformers |
■ konlpy 패키지를 설치하는 방법을 보여준다. 1. 명령 프롬프트를 실행한다. 2. 명령 프롬프트에서 아래 명령을 실행한다. ▶ 실행 명령
|
1 2 3 |
pip install konlpy |
■ pos_tag 함수를 사용해 단어 토큰 리스트의 단어 토큰에 태그를 설정한 단어 토큰/태그 튜플 리스트를 구하는 방법을 보여준다. ▶ main.py
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import nltk wordTokenList = nltk.word_tokenize("""덴마크 항구 도시에는 오래된 성이 하나 있다. 바로 외국인들은 엘시노어라고 알고 있는 '크론보르크 성'이다. 크론보르크는 덴마크와 스웨덴 사이에 있는 외레순 해협의 끝에 있었다.""" ) wordTokenTagTupleList = nltk.pos_tag(wordTokenList) print(wordTokenTagTupleList) """ [('덴마크', 'JJ'), ('항구', 'NNP'), ('도시에는', 'NNP'), ('오래된', 'NNP'), ('성이', 'NNP'), ('하나', 'NNP'), ('있다', 'NNP'), ('.', '.'), ('바로', 'VB'), ('외국인들은', 'JJ'), ('엘시노어라고', 'NNP'), ('알고', 'NNP'), ('있는', 'NNP'), ("'크론보르크", 'POS'), ("성'이다", 'NN'), ('.', '.'), ('크론보르크는', 'CC'), ('덴마크와', 'JJ'), ('스웨덴', 'NNP'), ('사이에', 'NNP'), ('있는', 'NNP'), ('외레순', 'NNP'), ('해협의', 'NNP'), ('끝에', 'NNP'), ('있었다', 'NNP'), ('.', '.')] """ |
▶
■ word_tokenize 함수를 사용해 단어 토큰 리스트를 구하는 방법을 보여준다. ▶ main.py
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import nltk wordTokenList = nltk.word_tokenize("""덴마크 항구 도시에는 오래된 성이 하나 있다. 바로 외국인들은 엘시노어라고 알고 있는 '크론보르크 성'이다. 크론보르크는 덴마크와 스웨덴 사이에 있는 외레순 해협의 끝에 있었다.""" ) print(wordTokenList) """ ['덴마크', '항구', '도시에는', '오래된', '성이', '하나', '있다', '.', '바로', '외국인들은', '엘시노어라고', '알고', '있는', "'크론보르크", "성'이다", '.', '크론보르크는', '덴마크와', '스웨덴', '사이에', '있는', '외레순', '해협의', '끝에', '있었다', '.'] """ |
▶ requirements.txt
|
1 2 3 4 5 6 7 |
click==8.1.7 joblib==1.4.2 nltk==3.8.1 regex==2024.5.15 tqdm==4.66.4 |
※ pip install nltk 명령을 실행했다.
■ download 함수를 사용해 특정 서브 패키지를 다운로드 받는 방법을 보여준다. ▶ main.py
|
1 2 3 4 5 6 |
import nltk nltk.download("punkt") nltk.download("averaged_perceptron_tagger") |
▶ 서브 패키지 목록
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 |
abc................. Australian Broadcasting Commission 2006 alpino.............. Alpino Dutch Treebank averaged_perceptron_tagger_ru Averaged Perceptron Tagger (Russian) basque_grammars..... Grammars for Basque bcp47............... BCP-47 Language Tags biocreative_ppi..... BioCreAtIvE (Critical Assessment of Information Extraction Systems in Biology) bllip_wsj_no_aux.... BLLIP Parser: WSJ Model book_grammars....... Grammars from NLTK Book brown............... Brown Corpus brown_tei........... Brown Corpus (TEI XML Version) cess_cat............ CESS-CAT Treebank cess_esp............ CESS-ESP Treebank chat80.............. Chat-80 Data Files city_database....... City Database cmudict............. The Carnegie Mellon Pronouncing Dictionary (0.6) comparative_sentences Comparative Sentence Dataset comtrans............ ComTrans Corpus Sample conll2000........... CONLL 2000 Chunking Corpus conll2002........... CONLL 2002 Named Entity Recognition Corpus conll2007........... Dependency Treebanks from CoNLL 2007 (Catalan and Basque Subset) crubadan............ Crubadan Corpus dependency_treebank. Dependency Parsed Treebank dolch............... Dolch Word List europarl_raw........ Sample European Parliament Proceedings Parallel Corpus extended_omw........ Extended Open Multilingual WordNet floresta............ Portuguese Treebank framenet_v15........ FrameNet 1.5 framenet_v17........ FrameNet 1.7 gazetteers.......... Gazeteer Lists genesis............. Genesis Corpus gutenberg........... Project Gutenberg Selections ieer................ NIST IE-ER DATA SAMPLE inaugural........... C-Span Inaugural Address Corpus indian.............. Indian Language POS-Tagged Corpus jeita............... JEITA Public Morphologically Tagged Corpus (in ChaSen format) kimmo............... PC-KIMMO Data Files knbc................ KNB Corpus (Annotated blog corpus) large_grammars...... Large context-free and feature-based grammars for parser comparison lin_thesaurus....... Lin's Dependency Thesaurus mac_morpho.......... MAC-MORPHO: Brazilian Portuguese news text with part-of-speech tags machado............. Machado de Assis -- Obra Completa masc_tagged......... MASC Tagged Corpus maxent_ne_chunker... ACE Named Entity Chunker (Maximum entropy) maxent_treebank_pos_tagger Treebank Part of Speech Tagger (Maximum entropy) moses_sample........ Moses Sample Models movie_reviews....... Sentiment Polarity Dataset Version 2.0 mte_teip5........... MULTEXT-East 1984 annotated corpus 4.0 mwa_ppdb............ The monolingual word aligner (Sultan et al. 2015) subset of the Paraphrase Database. names............... Names Corpus, Version 1.3 (1994-03-29) nombank.1.0......... NomBank Corpus 1.0 nonbreaking_prefixes Non-Breaking Prefixes (Moses Decoder) nps_chat............ NPS Chat omw-1.4............. Open Multilingual Wordnet omw................. Open Multilingua panlex_swadesh...... PanLex Swadesh Corpora paradigms........... Paradigm Corpus pe08................ Cross-Framework and Cross-Domain Parser Evaluation Shared Task perluniprops........ perluniprops: Index of Unicode Version 7.0.0 character properties in Perl pil................. The Patient Information Leaflet (PIL) Corpus pl196x.............. Polish language of the XX century sixties porter_test......... Porter Stemmer Test Files ppattach............ Prepositional Phrase Attachment Corpus problem_reports..... Problem Report Corpus product_reviews_1... Product Reviews (5 Products) product_reviews_2... Product Reviews (9 Products) propbank............ Proposition Bank Corpus 1.0 pros_cons........... Pros and Cons ptb................. Penn Treebank qc.................. Experimental Data for Question Classification reuters............. The Reuters-21578 benchmark corpus, ApteMod version rslp................ RSLP Stemmer (Removedor de Sufixos da Lingua Portuguesa) rte................. PASCAL RTE Challenges 1, 2, and 3 sample_grammars..... Sample Grammars semcor.............. SemCor 3.0 senseval............ SENSEVAL 2 Corpus: Sense Tagged Text sentence_polarity... Sentence Polarity Dataset v1.0 sentiwordnet........ SentiWordNet shakespeare......... Shakespeare XML Corpus Sample sinica_treebank..... Sinica Treebank Corpus Sample smultron............ SMULTRON Corpus Sample snowball_data....... Snowball Data spanish_grammars.... Grammars for Spanish state_union......... C-Span State of the Union Address Corpus stopwords........... Stopwords Corpus subjectivity........ Subjectivity Dataset v1.0 swadesh............. Swadesh Wordlists switchboard......... Switchboard Corpus Sample tagsets............. Help on Tagsets timit............... TIMIT Corpus Sample toolbox............. Toolbox Sample Files treebank............ Penn Treebank Sample twitter_samples..... Twitter Samples all-corpora......... All the corpora |
▶ requirements.txt
|
1 2 3 4 5 6 7 |
click==8.1.7 joblib==1.4.2 nltk==3.8.1 regex==2024.5.15 tqdm==4.66.4 |
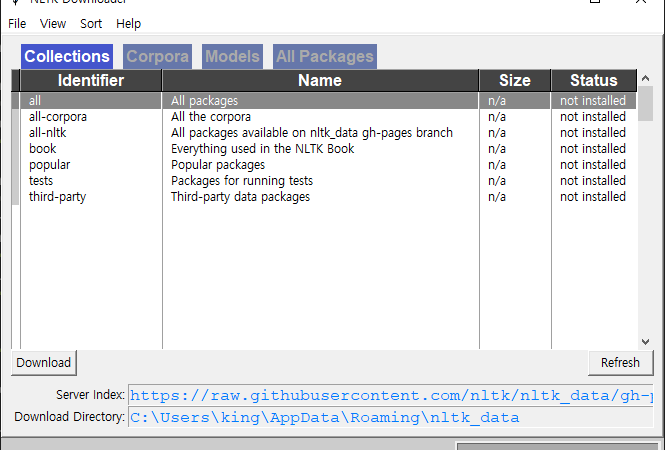
■ download 함수를 사용해 서브 패키지를 다운로드 받는 방법을 보여준다. ※ 윈도우즈나 우분투에서는 아래와 같은 윈도우가 표시되어서 서브 패키지를 다운로드 할 수
■ nltk 패키지를 설치하는 방법을 보여준다. 1. 명령 프롬프트를 실행한다. 2. 명령 프롬프트에서 아래 명령을 실행한다. ▶ 실행 명령
|
1 2 3 |
pip install nltk |