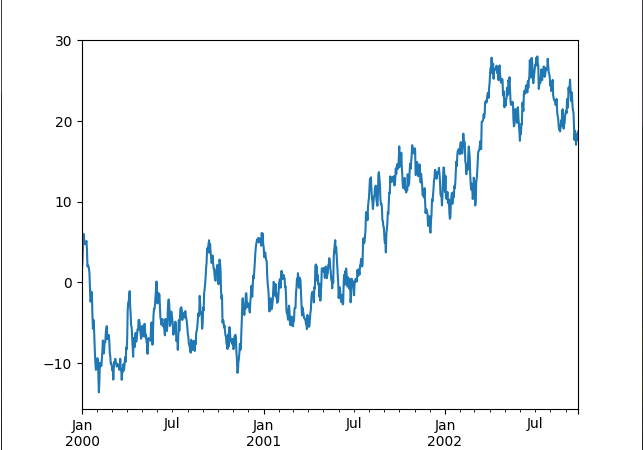
■ Series 클래스의 cumsum 메소드를 사용해 누적 합계를 구하는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
import pandas as pd import numpy as np import matplotlib.pyplot as plt datetimeIndex = pd.date_range("2000/01/01", periods = 1000) series1 = pd.Series(np.random.randn(1000), index = datetimeIndex) print(series1) """ 2000-01-01 1.605094 2000-01-02 1.032125 2000-01-03 2.041472 2000-01-04 1.341634 2000-01-05 -0.410063 ... 2002-09-22 -1.272603 2002-09-23 1.260618 2002-09-24 -0.654690 2002-09-25 0.085590 2002-09-26 0.936237 Freq: D, Length: 1000, dtype: float64 """ print() series2 = series1.cumsum() print(series2) """ 2000-01-01 1.605094 2000-01-02 2.637219 2000-01-03 4.678692 2000-01-04 6.020325 2000-01-05 5.610263 ... 2002-09-22 17.052849 2002-09-23 18.313467 2002-09-24 17.658777 2002-09-25 17.744367 2002-09-26 18.680604 Freq: D, Length: 1000, dtype: float64 """ series2.plot() plt.show() |
▶ requirements.txt
|
|
contourpy==1.3.0 cycler==0.12.1 fonttools==4.54.1 kiwisolver==1.4.7 matplotlib==3.9.2 numpy==2.1.3 packaging==24.2 pandas==2.2.3 pillow==11.0.0 pyparsing==3.2.0 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip install pandas matplotlib
더 읽기
■ close 함수를 사용해 모든 윈도우를 닫는 방법을 보여준다. ▶ main.py
|
|
import matplotlib.pyplot as plt plt.close("all") |
▶ requirements.txt
|
|
contourpy==1.3.0 cycler==0.12.1 fonttools==4.54.1 kiwisolver==1.4.7 matplotlib==3.9.2 numpy==2.1.3 packaging==24.2 pillow==11.0.0 pyparsing==3.2.0 python-dateutil==2.9.0.post0 six==1.16.0 |
※ pip install matplotlib 명령을 실행했다.
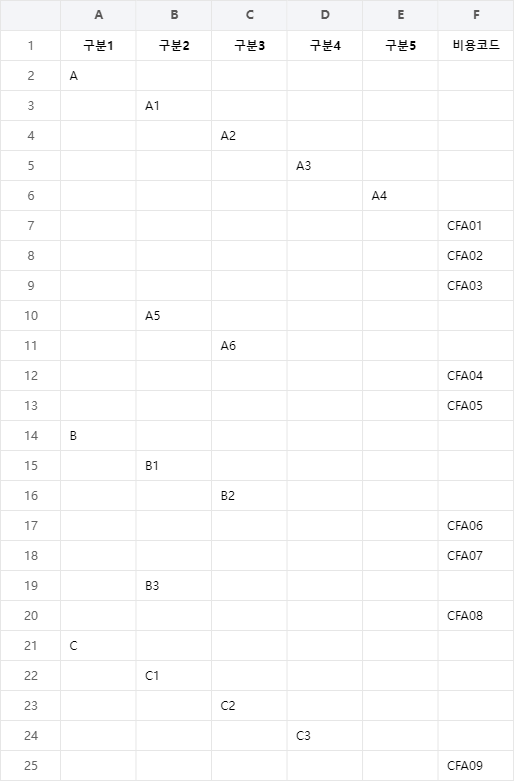
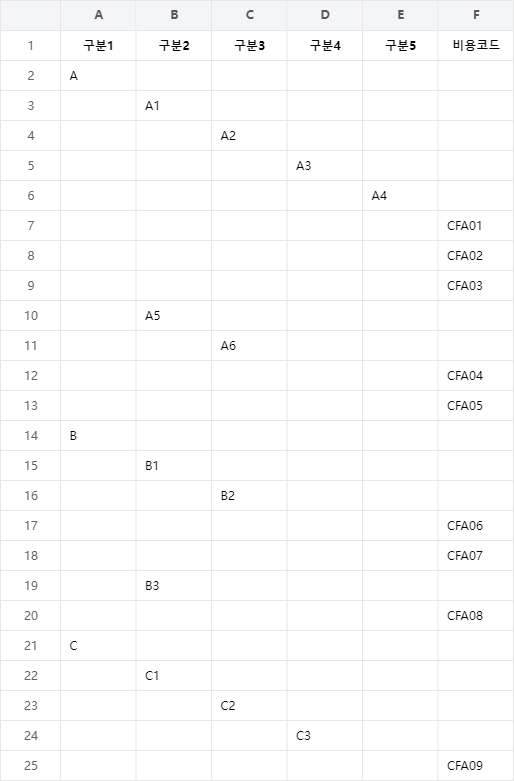
■ DataFrame 클래스의 groupby 메소드에서 observed 인자를 사용해 카테고리 컬럼을 집계하는 방법을 보여준다. ※ observed = False로 설정하면 카테고리 컬럼에서 값이 없는
더 읽기
■ DataFrame 클래스의 sort_values 메소드를 사용해 카테고리 컬럼을 정렬하는 방법을 보여준다. ※ 정렬은 어휘 순서가 아닌 범주별 순서에 따라 이루어진다. ▶ main.py
더 읽기
■ CategoricalAccessor 클래스의 set_categories 메소드를 사용해 카테고리 리스트를 설정하는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
import pandas as pd dataFrame = pd.DataFrame( { "id" : [1, 2, 3, 4, 5, 6], "raw_grade" : ["a", "b", "b", "a", "a", "e"] } ) dataFrame["grade"] = dataFrame["raw_grade"].astype("category") newCategoryList = ["very good", "good", "very bad"] series1 = dataFrame["grade"] categoricalAccessor1 = series1.cat dataFrame["grade"] = categoricalAccessor1.rename_categories(newCategoryList) series2 = dataFrame["grade"] categoricalAccessor2 = series2.cat dataFrame["grade"] = categoricalAccessor2.set_categories(["very bad", "bad", "medium", "good", "very good"]) print(dataFrame["grade"]) """ 0 very good 1 good 2 good 3 very good 4 very good 5 very bad Name: grade, dtype: category Categories (5, object): ['very bad', 'bad', 'medium', 'good', 'very good'] """ |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip install pandas 명령을
더 읽기
■ CategoricalAccessor 클래스의 rename_categories 메소드를 사용해 카테고리명을 변경하는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
import pandas as pd dataFrame = pd.DataFrame( { "id" : [1, 2, 3, 4, 5, 6], "raw_grade" : ["a", "b", "b", "a", "a", "e"] } ) dataFrame["grade"] = dataFrame["raw_grade"].astype("category") newCategoryList = ["very good", "good", "very bad"] series = dataFrame["grade"] categoricalAccessor = series.cat dataFrame["grade"] = categoricalAccessor.rename_categories(newCategoryList) print(dataFrame) """ id raw_grade grade 0 1 a very good 1 2 b good 2 3 b good 3 4 a very good 4 5 a very good 5 6 e very bad """ |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip install pandas 명령을 실행했다.
■ Series 클래스의 astype 메소드를 사용해 Series 객체의 dtype 속성을 category로 변경하는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
import pandas as pd dataFrame = pd.DataFrame( { "id" : [1, 2, 3, 4, 5, 6], "raw_grade" : ["a", "b", "b", "a", "a", "e"] } ) series1 = dataFrame["raw_grade"] series2 = series1.astype("category") dataFrame["grade"] = series2 print(dataFrame["grade"]) """ 0 a 1 b 2 b 3 a 4 a 5 e Name: grade, dtype: category Categories (3, object): ['a', 'b', 'e'] """ |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip
더 읽기
■ BusinessDay 클래스의 생성자를 사용해 BusinessDay 객체를 만드는 방법을 보여준다. ▶ main.py
|
|
import pandas as pd businessDay = pd.offsets.BusinessDay(5) print(businessDay) """ <5 * BusinessDays> """ |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip install pandas 명령을 실행했다.
■ DatetimeIndex 클래스에서 + 연산자를 사용해 BusinessDay 객체의 오프셋을 더하는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
import pandas as pd datetimeIndex1 = pd.date_range("2012/03/01 00:00:00", periods = 5, freq = "D") print(datetimeIndex1) """ DatetimeIndex(['2012-03-01', '2012-03-02', '2012-03-03', '2012-03-04', '2012-03-05'], dtype='datetime64[ns]', freq='D') """ print() datetimeIndex2 = datetimeIndex1 + pd.offsets.BusinessDay(5) print(datetimeIndex2) """ DatetimeIndex(['2012-03-08', '2012-03-09', '2012-03-09', '2012-03-09', '2012-03-12'], dtype='datetime64[ns]', freq=None) """ |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip install pandas
더 읽기
■ Series 클래스의 tz_convert 메소드를 사용해 시계열을 특정 시간대로 변환하는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
import pandas as pd import numpy as np datetimeIndex = pd.date_range("2012/03/01 00:00:00", periods = 5, freq = "3D") series1 = pd.Series(np.random.randn(len(datetimeIndex)), datetimeIndex) print(series1) """ 2012-03-01 -1.639957 2012-03-04 0.449630 2012-03-07 -1.289113 2012-03-10 -0.215940 2012-03-13 0.419875 Freq: 3D, dtype: float64 """ print() series2 = series1.tz_localize("UTC") print(series2) """ 2012-03-01 00:00:00+00:00 -1.639957 2012-03-04 00:00:00+00:00 0.449630 2012-03-07 00:00:00+00:00 -1.289113 2012-03-10 00:00:00+00:00 -0.215940 2012-03-13 00:00:00+00:00 0.419875 Freq: 3D, dtype: float64 """ print() series3 = series2.tz_convert("US/Eastern") print(series3) """ 2012-02-29 19:00:00-05:00 -1.639957 2012-03-03 19:00:00-05:00 0.449630 2012-03-06 19:00:00-05:00 -1.289113 2012-03-09 19:00:00-05:00 -0.215940 2012-03-12 20:00:00-04:00 0.419875 Freq: 3D, dtype: float64 """ |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip install pandas
더 읽기
■ Series 클래스의 tz_localize 메소드를 사용해 시계열을 특정 시간대로 설정하는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
import pandas as pd import numpy as np datetimeIndex = pd.date_range("2012/03/01 00:00:00", periods = 5, freq = "3D") series1 = pd.Series(np.random.randn(len(datetimeIndex)), datetimeIndex) print(series1) """ 2012-03-01 -1.639957 2012-03-04 0.449630 2012-03-07 -1.289113 2012-03-10 -0.215940 2012-03-13 0.419875 Freq: 3D, dtype: float64 """ print() series2 = series1.tz_localize("UTC") print(series2) """ 2012-03-01 00:00:00+00:00 -1.639957 2012-03-04 00:00:00+00:00 0.449630 2012-03-07 00:00:00+00:00 -1.289113 2012-03-10 00:00:00+00:00 -0.215940 2012-03-13 00:00:00+00:00 0.419875 Freq: 3D, dtype: float64 """ |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip install pandas
더 읽기
■ DatetimeIndexResampler 클래스의 sum 메소드를 사용해 시계열 특정 구간의 합계값을 구하는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
import pandas as pd import numpy as np datetimeIndex = pd.date_range("2012-01-01", periods = 100, freq = "s") series1 = pd.Series(np.random.randint(0, 500, len(datetimeIndex)), index = datetimeIndex) print(series1) """ 2012-01-01 00:00:00 470 2012-01-01 00:00:01 312 2012-01-01 00:00:02 54 2012-01-01 00:00:03 263 2012-01-01 00:00:04 214 ... 2012-01-01 00:01:35 432 2012-01-01 00:01:36 297 2012-01-01 00:01:37 2 2012-01-01 00:01:38 156 2012-01-01 00:01:39 176 Freq: s, Length: 100, dtype: int32 """ print() datetimeIndexResampler = series1.resample("5Min") series2 = datetimeIndexResampler.sum() print(series2) """ 2012-01-01 23670 Freq: 5min, dtype: int32 """ |
※ DatetimeIndexResampler 클래스에는 max 메소드 외에
더 읽기
■ Series 클래스의 unstack 메소드를 사용해 컬럼을 행으로 회전시켜 재구성한 것을 복원하는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 |
import pandas as pd import numpy as np valueListList = [ ["bar", "bar", "baz", "baz", "foo", "foo", "qux", "qux"], ["one", "two", "one", "two", "one", "two", "one", "two"] ] multiIndex = pd.MultiIndex.from_arrays(valueListList, names = ["first", "second"]) dataFrame1 = pd.DataFrame(np.random.randn(8, 2), index = multiIndex, columns = ["A", "B"]) print(dataFrame1) """ A B first second bar one 0.934435 1.055454 two -0.634130 1.229960 baz one -1.519993 1.254971 two -0.019397 0.182054 foo one 0.167189 0.165197 two -0.990571 -0.789641 qux one -0.922977 1.540567 two 1.213828 -1.346134 """ print() series = dataFrame1.stack(future_stack = True) # pandas 2.0.0 버전부터 도입된 새로운 구현 방식을 사용한다. print(series) """ first second bar one A 0.934435 B 1.055454 two A -0.634130 B 1.229960 baz one A -1.519993 B 1.254971 two A -0.019397 B 0.182054 foo one A 0.167189 B 0.165197 two A -0.990571 B -0.789641 qux one A -0.922977 B 1.540567 two A 1.213828 B -1.346134 dtype: float64 """ print() dataFrame2 = series.unstack() # 기본적으로 마지막 레벨을 언스택한다. print(dataFrame2) """ A B first second bar one 0.934435 1.055454 two -0.634130 1.229960 baz one -1.519993 1.254971 two -0.019397 0.182054 foo one 0.167189 0.165197 two -0.990571 -0.789641 qux one -0.922977 1.540567 two 1.213828 -1.346134 """ print() dataFrame3 = series.unstack(1) # 1번 레벨을 언스택한다. print(dataFrame3) """ second one two first bar A 0.934435 -0.634130 B 1.055454 1.229960 baz A -1.519993 -0.019397 B 1.254971 0.182054 foo A 0.167189 -0.990571 B 0.165197 -0.789641 qux A -0.922977 1.213828 B 1.540567 -1.346134 """ print() dataFrame4 = series.unstack(0) # 0번 레벨을 언스택한다. print(dataFrame4) """ first bar baz foo qux second one A 0.934435 -1.519993 0.167189 -0.922977 B 1.055454 1.254971 0.165197 1.540567 two A -0.634130 -0.019397 -0.990571 1.213828 B 1.229960 0.182054 -0.789641 -1.346134 """ |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip
더 읽기
■ DataFrame 클래스의 stack 메소드를 사용해 컬럼을 행으로 회전시켜 재구성하는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
import pandas as pd import numpy as np valueListList = [ ["bar", "bar", "baz", "baz", "foo", "foo", "qux", "qux"], ["one", "two", "one", "two", "one", "two", "one", "two"] ] multiIndex = pd.MultiIndex.from_arrays(valueListList, names = ["first", "second"]) dataFrame = pd.DataFrame(np.random.randn(8, 2), index = multiIndex, columns = ["A", "B"]) series = dataFrame.stack(future_stack = True) print(series) """ first second bar one A 1.584979 B 0.722164 two A -0.732636 B -0.972243 baz one A -0.563416 B -0.132313 two A 0.539319 B -0.272648 foo one A 2.486126 B -1.175791 two A 1.639742 B -0.272356 qux one A 1.700369 B 0.075727 two A 0.802515 B 0.624844 dtype: float64 """ |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip install pandas
더 읽기
■ DataFrame 클래스의 생성자에서 index 인자에 MultiIndex 객체를 설정해 복수 인덱스 컬럼을 설정하는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
import pandas as pd import numpy as np valueListList = [ ["bar", "bar", "baz", "baz", "foo", "foo", "qux", "qux"], ["one", "two", "one", "two", "one", "two", "one", "two"] ] multiIndex = pd.MultiIndex.from_arrays(valueListList, names = ["first", "second"]) dataFrame = pd.DataFrame(np.random.randn(8, 2), index = multiIndex, columns = ["A", "B"]) print(dataFrame) """ A B first second bar one 0.750921 0.389984 two 0.698129 0.758190 baz one -0.916464 0.077477 two -1.166463 -0.051377 foo one -1.013851 1.058877 two -0.099774 -0.408415 qux one 0.706805 0.007168 two 0.134635 2.517938 """ |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※
더 읽기
■ MultiIndex 클래스의 from_arrays 정적 메소드에서 names 인자를 사용해 MultiIndex 객체를 만드는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
import pandas as pd valueListList = [ ["bar", "bar", "baz", "baz", "foo", "foo", "qux", "qux"], ["one", "two", "one", "two", "one", "two", "one", "two"] ] multiIndex = pd.MultiIndex.from_arrays(valueListList, names = ["first", "second"]) print(multiIndex) """ MultiIndex([('bar', 'one'), ('bar', 'two'), ('baz', 'one'), ('baz', 'two'), ('foo', 'one'), ('foo', 'two'), ('qux', 'one'), ('qux', 'two')], names=['first', 'second']) """ |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip
더 읽기
■ concat 함수를 사용해 N개의 DataFrame 객체를 순서대로 결합하는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
import pandas as pd import numpy as np dataFrame1 = pd.DataFrame(np.random.randn(10, 4)) print(dataFrame1) """ 0 1 2 3 0 0.792127 -1.345781 1.426220 -0.373232 1 -0.405740 1.017649 -1.425406 -0.210875 2 -1.441189 -1.933996 0.498967 0.125154 3 0.794920 0.183752 0.315564 -0.169499 4 0.137222 -0.541917 0.647770 0.446726 5 0.369762 -1.091014 0.281678 1.570859 6 0.381293 0.076755 0.528035 0.708578 7 -1.452200 -1.163749 -0.571872 0.239115 8 -2.380354 -1.172107 0.225631 0.613133 9 0.777913 1.788713 -0.383232 0.489444 """ print() dataFrameList = [dataFrame1[:3], dataFrame1[3:7], dataFrame1[7:]] dataFrame2 = pd.concat(dataFrameList) print(dataFrame2) """ 0 1 2 3 0 0.792127 -1.345781 1.426220 -0.373232 1 -0.405740 1.017649 -1.425406 -0.210875 2 -1.441189 -1.933996 0.498967 0.125154 3 0.794920 0.183752 0.315564 -0.169499 4 0.137222 -0.541917 0.647770 0.446726 5 0.369762 -1.091014 0.281678 1.570859 6 0.381293 0.076755 0.528035 0.708578 7 -1.452200 -1.163749 -0.571872 0.239115 8 -2.380354 -1.172107 0.225631 0.613133 9 0.777913 1.788713 -0.383232 0.489444 """ |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip install pandas 명령을
더 읽기
■ ndenumerate 함수를 사용해 배열 항목을 나열하는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
import numpy as np list1 = list(range(1, 24)) + [np.nan] ndarray1 = np.array(list1) ndarray2 = ndarray1.reshape(2, 3, 4) for indexTuple, value in np.ndenumerate(ndarray2): print(indexTuple, value) """ (0, 0, 0) 1.0 (0, 0, 1) 2.0 (0, 0, 2) 3.0 (0, 0, 3) 4.0 (0, 1, 0) 5.0 (0, 1, 1) 6.0 (0, 1, 2) 7.0 (0, 1, 3) 8.0 (0, 2, 0) 9.0 (0, 2, 1) 10.0 (0, 2, 2) 11.0 (0, 2, 3) 12.0 (1, 0, 0) 13.0 (1, 0, 1) 14.0 (1, 0, 2) 15.0 (1, 0, 3) 16.0 (1, 1, 0) 17.0 (1, 1, 1) 18.0 (1, 1, 2) 19.0 (1, 1, 3) 20.0 (1, 2, 0) 21.0 (1, 2, 1) 22.0 (1, 2, 2) 23.0 (1, 2, 3) nan """ |
▶ requirements.txt
※ pip install numpy 명령을 실행했다.
■ randint 함수를 사용해 정수 난수 배열을 만드는 방법을 보여준다. ▶ main.py
|
|
import numpy as np ndarray1 = np.random.randint(0, 7, size = 10) # 0부터 6 사이 정수 난수 10개 추출 print(ndarray1) """ [3 6 2 4 4 2 3 6 0 4] """ |
▶ requirements.txt
※ pip install numpy 명령을 실행했다.
■ Series 클래스의 value_counts 메소드를 사용해 특정 항목 값에 대한 데이터 수를 구하는 방법을 보여준다. ※ value_counts 메소드는 dropna 인수를 사용하여 NaN
더 읽기
■ DataFrame 클래스의 transform 메소드에서 lambda 함수를 사용해 컬럼 값을 변경하는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
import pandas as pd import numpy as np datetimeIndex = pd.date_range("20130101", periods = 6) dataFrame1 = pd.DataFrame(np.random.randn(6, 4), index = datetimeIndex, columns = list("ABCD")) print(dataFrame1) """ A B C D 2013-01-01 -0.348191 -1.264788 -0.162901 1.103283 2013-01-02 -0.524437 1.183184 -0.312923 2.145154 2013-01-03 0.230208 0.493941 1.820556 -1.041067 2013-01-04 0.399232 0.570309 -0.269344 -1.350358 2013-01-05 -0.785327 -1.059529 -0.642831 -1.075879 2013-01-06 -1.255896 0.641685 2.065610 0.004382 """ print() dataFrame2 = dataFrame1.transform(lambda x : x * 101.2) print(dataFrame2) """ A B C D 2013-01-01 -35.236936 -127.996495 -16.485594 111.652235 2013-01-02 -53.073035 119.738185 -31.667851 217.089579 2013-01-03 23.297028 49.986860 184.240241 -105.355954 2013-01-04 40.402308 57.715234 -27.257620 -136.656259 2013-01-05 -79.475111 -107.224318 -65.054500 -108.878999 2013-01-06 -127.096632 64.938487 209.039739 0.443483 """ |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip install
더 읽기
■ DataFrame 클래스의 agg 메소드에서 lambda 함수를 커스텀 집계 함수로 사용하는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
import pandas as pd import numpy as np datetimeIndex = pd.date_range("20130101", periods = 6) dataFrame = pd.DataFrame(np.random.randn(6, 4), index = datetimeIndex, columns = list("ABCD")) print(dataFrame) """ A B C D 2013-01-01 0.389016 1.940161 0.821590 -0.026517 2013-01-02 -0.393310 2.111965 0.392065 0.177232 2013-01-03 -0.434576 0.289613 -0.507643 0.838895 2013-01-04 0.177708 -0.698036 0.195119 -1.447753 2013-01-05 0.536391 2.427713 0.306881 0.999480 2013-01-06 2.339590 -1.860456 -1.482091 0.046616 """ print() series = dataFrame.agg(lambda x : np.mean(x) * 5.6) print(series) """ A 2.440498 B 3.930228 C -0.255807 D 0.548755 dtype: float64 """ |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip install
더 읽기
■ DataFrame 클래스의 sub 메소드에서 axis 인자를 사용해 뺄셈하는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
import pandas as pd import numpy as np datetimeIndex = pd.date_range("20130101", periods = 6) dataFrame1 = pd.DataFrame(np.random.randn(6, 4), index = datetimeIndex, columns = list("ABCD")) print(dataFrame1) """ A B C D 2013-01-01 1.727789 0.330913 0.705797 0.987456 2013-01-02 -1.074524 0.247558 0.989254 1.718233 2013-01-03 0.498621 0.341959 0.171567 -0.567567 2013-01-04 -1.395337 0.952481 -0.019128 0.993886 2013-01-05 1.593197 0.803565 -0.327899 1.062228 2013-01-06 -2.427016 0.580813 -1.242874 0.772521 """ print() series1 = pd.Series([1, 3, 5, np.nan, 6, 8], index = datetimeIndex) series2 = series1.shift(2) print(series2) """ 2013-01-01 NaN 2013-01-02 NaN 2013-01-03 1.0 2013-01-04 3.0 2013-01-05 5.0 2013-01-06 NaN Freq: D, dtype: float64 """ dataFrame2 = dataFrame1.sub(series2, axis = "index") print(dataFrame2) """ A B C D 2013-01-01 NaN NaN NaN NaN 2013-01-02 NaN NaN NaN NaN 2013-01-03 -0.501379 -0.658041 -0.828433 -1.567567 2013-01-04 -4.395337 -2.047519 -3.019128 -2.006114 2013-01-05 -3.406803 -4.196435 -5.327899 -3.937772 2013-01-06 NaN NaN NaN NaN """ |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip install pandas 명령을
더 읽기
■ Series 클래스의 shift 메소드를 사용해 값을 이동시키는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
import pandas as pd import numpy as np datetimeIndex = pd.date_range("20130101", periods = 6) series1 = pd.Series([1, 3, 5, np.nan, 6, 8], index = datetimeIndex) series2 = series1.shift(2) print(series2) """ 2013-01-01 NaN 2013-01-02 NaN 2013-01-03 1.0 2013-01-04 3.0 2013-01-05 5.0 2013-01-06 NaN Freq: D, dtype: float64 """ |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip install pandas 명령을 실행했다.
■ DataFrame 클래스의 mean 메소드에서 axis 인자를 사용해 각 행의 평균값을 구하는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
import pandas as pd import numpy as np datetimeIndex = pd.date_range("20130101", periods = 6) dataFrame = pd.DataFrame(np.random.randn(6, 4), index = datetimeIndex, columns = list("ABCD")) print(dataFrame) """ A B C D 2013-01-01 -1.517341 1.581524 -1.732825 0.722582 2013-01-02 -0.436266 -0.213191 0.776858 1.455175 2013-01-03 1.393637 -0.589855 -0.039133 -0.290809 2013-01-04 -0.131246 0.192069 0.298770 -1.808248 2013-01-05 0.351107 0.183434 -0.330830 0.121437 2013-01-06 -0.314445 0.392157 -2.171396 1.147362 """ print() series = dataFrame.mean(axis = 1) # axis : 0(행), 1(컬럼) print(series) """ 2013-01-01 -0.236515 2013-01-02 0.395644 2013-01-03 0.118460 2013-01-04 -0.362164 2013-01-05 0.081287 2013-01-06 -0.236580 Freq: D, dtype: float64 """ |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip
더 읽기