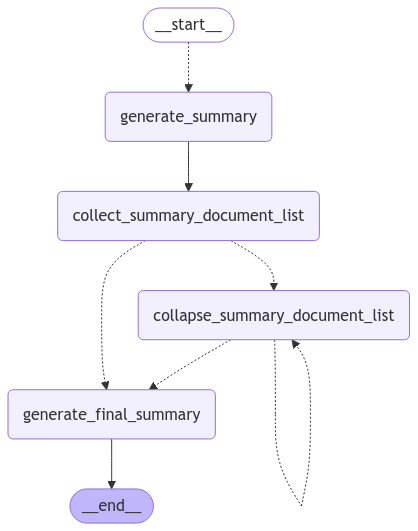
■ DataFrame 클래스의 mean 메소드를 사용해 각 컬럼의 평균값을 구하는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
import pandas as pd import numpy as np datetimeIndex = pd.date_range("20130101", periods = 6) dataFrame = pd.DataFrame(np.random.randn(6, 4), index = datetimeIndex, columns = list("ABCD")) print(dataFrame) """ A B C D 2013-01-01 -0.427331 -0.372399 0.195643 -0.280798 2013-01-02 0.788336 -0.135781 -0.407083 -0.411756 2013-01-03 -1.350004 -1.162144 -0.036725 0.311316 2013-01-04 -1.433128 -0.333235 2.136542 1.440727 2013-01-05 -0.579444 -0.868167 0.041668 0.019251 2013-01-06 -0.576273 1.069613 1.486077 -1.053925 """ print() series = dataFrame.mean() print(series) """ A -0.596307 B -0.300352 C 0.569354 D 0.004136 dtype: float64 """ |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip install pandas
더 읽기
■ DataFrame 클래스의 reindex 메소드에서 index/columns 인자를 사용해 인덱스/컬럼을 재구성하는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
import pandas as pd import numpy as np datetimeIndex = pd.date_range("20130101", periods = 6) dataFrame1 = pd.DataFrame(np.random.randn(6, 4), index = datetimeIndex, columns = list("ABCD")) print(dataFrame1) """ A B C D 2013-01-01 -0.273991 0.146700 -0.962881 0.531161 2013-01-02 -0.018018 1.398183 -0.601010 -1.012397 2013-01-03 -0.692638 3.078527 0.164985 -0.842357 2013-01-04 -0.492567 -0.533595 -1.081510 -1.283123 2013-01-05 0.003707 -1.165857 1.957604 -0.203697 2013-01-06 0.474054 2.345456 0.426076 0.330338 """ print() dataFrame2 = dataFrame1.reindex(index = datetimeIndex[0:4], columns = list(dataFrame1.columns) + ["E"]) print(dataFrame2) """ A B C D E 2013-01-01 -0.273991 0.146700 -0.962881 0.531161 NaN 2013-01-02 -0.018018 1.398183 -0.601010 -1.012397 NaN 2013-01-03 -0.692638 3.078527 0.164985 -0.842357 NaN 2013-01-04 -0.492567 -0.533595 -1.081510 -1.283123 NaN """ |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip install pandas
더 읽기
■ DataFrame 클래스에서 [] 연산자를 사용해 양수 값을 음수 값으로 변경하는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
import pandas as pd import numpy as np datetimeIndex = pd.date_range("20130101", periods = 6) dataFrame = pd.DataFrame(np.random.randn(6, 4), index = datetimeIndex, columns = list("ABCD")) print(dataFrame) """ A B C D 2013-01-01 -2.415582 -0.520550 -1.801407 0.689429 2013-01-02 0.945648 1.536237 -1.778640 0.202120 2013-01-03 0.568660 1.233407 -1.016520 0.733999 2013-01-04 -0.290816 1.417348 -0.050532 -0.024839 2013-01-05 -0.611079 0.372267 1.136837 -2.772960 2013-01-06 2.101773 -0.337019 1.035544 -1.979480 """ print() dataFrame[dataFrame > 0] = -dataFrame print(dataFrame) """ A B C D 2013-01-01 -2.415582 -0.520550 -1.801407 -0.689429 2013-01-02 -0.945648 -1.536237 -1.778640 -0.202120 2013-01-03 -0.568660 -1.233407 -1.016520 -0.733999 2013-01-04 -0.290816 -1.417348 -0.050532 -0.024839 2013-01-05 -0.611079 -0.372267 -1.136837 -2.772960 2013-01-06 -2.101773 -0.337019 -1.035544 -1.979480 """ |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip install
더 읽기
■ DataFrame 클래스의 loc 속성을 사용해 특정 컬럼의 데이터를 변경하는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
import pandas as pd import numpy as np datetimeIndex = pd.date_range("20130101", periods = 6) dataFrame = pd.DataFrame(np.random.randn(6, 4), index = datetimeIndex, columns = list("ABCD")) print(dataFrame) """ A B C D 2013-01-01 -1.024513 2.729313 0.866363 0.781470 2013-01-02 -0.594614 -0.238171 -0.041801 -0.337448 2013-01-03 -0.168112 -0.125254 0.037904 0.376932 2013-01-04 0.462503 0.292850 -1.011982 1.821977 2013-01-05 -1.207941 -0.644128 -2.173165 -0.039098 2013-01-06 0.684733 0.323357 1.083395 0.600062 """ print() dataFrame.loc[:, "D"] = np.array([5] * len(dataFrame)) print(dataFrame) """ A B C D 2013-01-01 -1.024513 2.729313 0.866363 5.0 2013-01-02 -0.594614 -0.238171 -0.041801 5.0 2013-01-03 -0.168112 -0.125254 0.037904 5.0 2013-01-04 0.462503 0.292850 -1.011982 5.0 2013-01-05 -1.207941 -0.644128 -2.173165 5.0 2013-01-06 0.684733 0.323357 1.083395 5.0 """ |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip install pandas
더 읽기
■ DataFrame 클래스의 iat 속성을 사용해 특정 셀의 데이터를 구하는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
import pandas as pd import numpy as np datetimeIndex = pd.date_range("20130101", periods = 6) dataFrame1 = pd.DataFrame(np.random.randn(6, 4), index = datetimeIndex, columns = list("ABCD")) print(dataFrame1) """ A B C D 2013-01-01 0.248786 -0.657086 0.370225 -0.780453 2013-01-02 0.312765 -0.492724 0.654803 1.203754 2013-01-03 0.523139 -2.126527 0.553737 0.041873 2013-01-04 1.316598 0.422930 0.354900 -0.610110 2013-01-05 1.354282 -0.052645 0.497243 -0.943024 2013-01-06 -0.590947 0.494301 -0.692021 -0.128895 """ print() cellValue = dataFrame1.iat[1, 1] # numpy.float64 print(cellValue) """ -0.49272407509029337 """ |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip install pandas
더 읽기
■ DataFrame 클래스의 iloc 속성을 사용해 컬럼을 명시적으로 슬라이싱하는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
import pandas as pd import numpy as np datetimeIndex = pd.date_range("20130101", periods = 6) dataFrame1 = pd.DataFrame(np.random.randn(6, 4), index = datetimeIndex, columns = list("ABCD")) print(dataFrame1) """ A B C D 2013-01-01 -0.418967 -0.833904 -1.134466 1.835324 2013-01-02 -0.868156 1.606709 -0.455127 -0.484539 2013-01-03 -1.772179 -0.491787 2.472023 0.353378 2013-01-04 -1.455474 0.054363 0.405077 -1.180987 2013-01-05 0.787927 -1.620420 1.945740 -0.311787 2013-01-06 -2.274122 1.185262 -0.923877 -0.539917 """ print() dataFrame2 = dataFrame1.iloc[:, 1:3] print(dataFrame2) """ B C 2013-01-01 -0.833904 -1.134466 2013-01-02 1.606709 -0.455127 2013-01-03 -0.491787 2.472023 2013-01-04 0.054363 0.405077 2013-01-05 -1.620420 1.945740 2013-01-06 1.185262 -0.923877 """ |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip install pandas 명령을
더 읽기
■ DataFrame 클래스의 iloc 속성을 사용해 행을 명시적으로 슬라이싱하는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
import pandas as pd import numpy as np datetimeIndex = pd.date_range("20130101", periods = 6) dataFrame1 = pd.DataFrame(np.random.randn(6, 4), index = datetimeIndex, columns = list("ABCD")) print(dataFrame1) """ A B C D 2013-01-01 1.319131 1.050159 -0.329930 0.218507 2013-01-02 0.313371 -0.866423 0.648042 0.088910 2013-01-03 0.569949 -0.366839 -0.384350 0.130825 2013-01-04 -0.623062 -0.461133 1.438269 -0.315030 2013-01-05 -0.987991 0.187271 -0.835588 1.024690 2013-01-06 0.554150 1.119017 -0.064934 1.074642 """ print() dataFrame2 = dataFrame1.iloc[1:3, :] print(dataFrame2) """ A B C D 2013-01-02 0.313371 -0.866423 0.648042 0.088910 2013-01-03 0.569949 -0.366839 -0.384350 0.130825 """ |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip install pandas 명령을
더 읽기
■ DataFrame 클래스의 iloc 속성을 사용해 특정 행/컬럼의 데이터를 구하는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
import pandas as pd import numpy as np datetimeIndex = pd.date_range("20130101", periods = 6) dataFrame1 = pd.DataFrame(np.random.randn(6, 4), index = datetimeIndex, columns = list("ABCD")) print(dataFrame1) """ A B C D 2013-01-01 -1.076450 0.098831 0.331691 -1.270272 2013-01-02 -0.698761 -0.281936 1.356855 1.439182 2013-01-03 -0.060443 -2.536983 0.474903 0.852891 2013-01-04 0.483600 1.162260 -0.438379 -0.323761 2013-01-05 -1.067515 -0.316740 0.400269 0.318582 2013-01-06 -1.215142 1.216324 -0.214613 0.780061 """ print() dataFrame2 = dataFrame1.iloc[[1, 2, 4], [0, 2]] print(dataFrame2) """ A C 2013-01-02 -0.698761 1.356855 2013-01-03 -0.060443 0.474903 2013-01-05 -1.067515 0.400269 """ |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip install pandas
더 읽기
■ DataFrame 클래스의 at 속성을 사용해 특정 셀의 데이터를 구하는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
import pandas as pd import numpy as np datetimeIndex = pd.date_range("20130101", periods = 6) dataFrame1 = pd.DataFrame(np.random.randn(6, 4), index = datetimeIndex, columns = list("ABCD")) print(dataFrame1) """ A B C D 2013-01-01 1.496475 -0.462460 0.239277 -0.150066 2013-01-02 0.522467 -1.208454 -0.249313 0.337069 2013-01-03 -0.058117 0.351514 2.003000 -1.487527 2013-01-04 -2.049386 0.991963 -1.148437 -0.631090 2013-01-05 0.284946 1.314614 -1.701463 1.685527 2013-01-06 -2.020866 0.165436 1.581737 0.480128 """ print() value = dataFrame1.at[datetimeIndex[0], "A"] print(value) """ 1.4964751609479943 """ |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip install pandas
더 읽기
■ DataFrame 클래스의 loc 속성을 사용해 특정 컬럼의 데이터를 구하는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
import pandas as pd import numpy as np datetimeIndex = pd.date_range("20130101", periods = 6) dataFrame1 = pd.DataFrame(np.random.randn(6, 4), index = datetimeIndex, columns = list("ABCD")) print(dataFrame1) """ A B C D 2013-01-01 -0.453182 -0.861583 -0.254588 -0.361769 2013-01-02 1.215367 0.103539 0.098492 0.149869 2013-01-03 0.821661 -1.125507 -0.242997 0.911715 2013-01-04 0.642376 0.346627 -0.750569 -1.202167 2013-01-05 -1.837095 -0.145270 0.976675 0.339294 2013-01-06 -1.088314 0.103322 0.846974 -1.413636 """ print() dataFrame2 = dataFrame1.loc["20130102":"20130104", ["A", "B"]] print(dataFrame2) """ A B 2013-01-02 1.215367 0.103539 2013-01-03 0.821661 -1.125507 2013-01-04 0.642376 0.346627 """ |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip install pandas
더 읽기
■ DataFrame 클래스의 loc 속성을 사용해 특정 컬럼의 데이터를 구하는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
import pandas as pd import numpy as np datetimeIndex = pd.date_range("20130101", periods = 6) dataFrame1 = pd.DataFrame(np.random.randn(6, 4), index = datetimeIndex, columns = list("ABCD")) print(dataFrame1) """ A B C D 2013-01-01 -0.012239 -1.219733 0.329373 -0.727080 2013-01-02 -0.174491 -0.052405 0.713403 0.700079 2013-01-03 0.446779 -1.130175 -0.506828 -1.090990 2013-01-04 -0.150186 1.009573 0.664691 1.069907 2013-01-05 2.260466 0.023234 -1.803731 2.082104 2013-01-06 -0.082471 -0.077965 0.253575 -0.043752 """ print() dataFrame2 = dataFrame1.loc[:, ["A", "B"]] print(dataFrame2) """ A B 2013-01-01 -0.012239 -1.219733 2013-01-02 -0.174491 -0.052405 2013-01-03 0.446779 -1.130175 2013-01-04 -0.150186 1.009573 2013-01-05 2.260466 0.023234 2013-01-06 -0.082471 -0.077965 """ |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip install pandas
더 읽기
■ DataFrame 클래스의 loc 속성을 사용해 첫번째 데이터를 구하는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
import pandas as pd import numpy as np datetimeIndex = pd.date_range("20130101", periods = 6) dataFrame = pd.DataFrame(np.random.randn(6, 4), index = datetimeIndex, columns = list("ABCD")) print(dataFrame) """ A B C D 2013-01-01 1.158410 0.258659 -0.430055 -2.096008 2013-01-02 0.000879 -0.127080 -0.212951 1.275311 2013-01-03 1.675983 -2.314498 -1.101046 -1.161565 2013-01-04 -0.325405 -2.769847 0.648851 0.535671 2013-01-05 -2.115589 -0.763019 0.626654 0.984163 2013-01-06 -0.830564 1.661675 -0.351440 -0.423769 """ print() series = dataFrame.loc[datetimeIndex[0]] print(series) """ A 1.158410 B 0.258659 C -0.430055 D -2.096008 Name: 2013-01-01 00:00:00, dtype: float64 """ |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip install pandas 명령을
더 읽기
■ DataFrame 클래스의 sort_index 메소드에서 axis/ascending 인자를 사용해 컬럼 축 기준 컬럼명을 정렬하는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
import pandas as pd import numpy as np dataFrame1 = pd.DataFrame( { "A" : 1.0, "B" : pd.Timestamp("20130102"), "C" : pd.Series(1, index = list(range(4)), dtype = "float32"), "D" : np.array([3] * 4, dtype = "int32"), "E" : pd.Categorical(["test", "train", "test", "train"]), "F" : "foo" } ) print(dataFrame1) """ A B C D E F 0 1.0 2013-01-02 1.0 3 test foo 1 1.0 2013-01-02 1.0 3 train foo 2 1.0 2013-01-02 1.0 3 test foo 3 1.0 2013-01-02 1.0 3 train foo """ print() dataFrame2 = dataFrame1.sort_index(axis = 1, ascending = False) # axis : 0(행 기준), 1(열 기준) print(dataFrame2) """ F E D C B A 0 foo test 3 1.0 2013-01-02 1.0 1 foo train 3 1.0 2013-01-02 1.0 2 foo test 3 1.0 2013-01-02 1.0 3 foo train 3 1.0 2013-01-02 1.0 """ |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※
더 읽기
■ DataFrame 클래스의 T 속성을 사용해 데이터를 전치하는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
import pandas as pd import numpy as np dataFrame = pd.DataFrame( { "A" : 1.0, "B" : pd.Timestamp("20130102"), "C" : pd.Series(1, index = list(range(4)), dtype = "float32"), "D" : np.array([3] * 4, dtype = "int32"), "E" : pd.Categorical(["test", "train", "test", "train"]), "F" : "foo" } ) print(dataFrame) """ A B C D E F 0 1.0 2013-01-02 1.0 3 test foo 1 1.0 2013-01-02 1.0 3 train foo 2 1.0 2013-01-02 1.0 3 test foo 3 1.0 2013-01-02 1.0 3 train foo """ print() print(dataFrame.T) """ 0 1 2 3 A 1.0 1.0 1.0 1.0 B 2013-01-02 00:00:00 2013-01-02 00:00:00 2013-01-02 00:00:00 2013-01-02 00:00:00 C 1.0 1.0 1.0 1.0 D 3 3 3 3 E test train test train F foo foo foo foo """ |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip install pandas 명령을 실행했다.
■ DataFrame 클래스의 to_numpy 메소드를 사용해 ndarray 객체를 구하는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
import pandas as pd import numpy as np dataFrame = pd.DataFrame( { "A" : 1.0, "B" : pd.Timestamp("20130102"), "C" : pd.Series(1, index = list(range(4)), dtype = "float32"), "D" : np.array([3] * 4, dtype = "int32"), "E" : pd.Categorical(["test", "train", "test", "train"]), "F" : "foo" } ) print(dataFrame) """ A B C D E F 0 1.0 2013-01-02 1.0 3 test foo 1 1.0 2013-01-02 1.0 3 train foo 2 1.0 2013-01-02 1.0 3 test foo 3 1.0 2013-01-02 1.0 3 train foo """ ndarray1 = dataFrame.to_numpy() print(ndarray1) """ [[1.0 Timestamp('2013-01-02 00:00:00') 1.0 3 'test' 'foo'] [1.0 Timestamp('2013-01-02 00:00:00') 1.0 3 'train' 'foo'] [1.0 Timestamp('2013-01-02 00:00:00') 1.0 3 'test' 'foo'] [1.0 Timestamp('2013-01-02 00:00:00') 1.0 3 'train' 'foo']] """ |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip install pandas 명령을
더 읽기
■ DataFrame 클래스의 생성자를 사용해 다양한 데이터 타입의 컬럼을 갖는 DataFrame 객체를 만드는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
import pandas as pd import numpy as np dataFrame = pd.DataFrame( { "A" : 1.0, "B" : pd.Timestamp("20130102"), "C" : pd.Series(1, index = list(range(4)), dtype = "float32"), "D" : np.array([3] * 4, dtype = "int32"), "E" : pd.Categorical(["test", "train", "test", "train"]), "F" : "foo" } ) print(dataFrame) """ A B C D E F 0 1.0 2013-01-02 1.0 3 test foo 1 1.0 2013-01-02 1.0 3 train foo 2 1.0 2013-01-02 1.0 3 test foo 3 1.0 2013-01-02 1.0 3 train foo """ |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※
더 읽기
■ Categorical 클래스의 생성자를 사용해 Categorical 객체를 만드는 방법을 보여준다. ▶ main.py
|
|
import pandas as pd categorical = pd.Categorical(["test", "train", "test", "train"]) print(categorical) """ ['test', 'train', 'test', 'train'] Categories (2, object): ['test', 'train'] """ |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip install pandas 명령을 실행했다.
■ DataFrame 클래스의 생성자에서 index/columns 인자를 사용해 DataFrame 객체를 만드는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
import pandas as pd import numpy as np datetimeIndex = pd.date_range("20130101", periods = 6) ndarray1 = np.random.randn(6, 4) # 6행 4열 배열 dataFrame = pd.DataFrame(ndarray1, index = datetimeIndex, columns = list("ABCD")) print(dataFrame) """ A B C D 2013-01-01 0.379704 0.640741 -2.602984 -1.576275 2013-01-02 -1.400774 1.519939 0.563043 -0.498297 2013-01-03 1.190896 0.389969 -1.515588 0.745648 2013-01-04 0.175308 -0.416092 -0.360387 0.647819 2013-01-05 -0.187323 0.036568 0.392615 -1.870158 2013-01-06 1.161280 -1.250679 0.877178 1.321106 """ |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip install pandas
더 읽기
■ date_range 함수의 periods 인자를 사용해 DatetimeIndex 객체를 만드는 방법을 보여준다. ▶ main.py
|
|
import pandas as pd datetimeIndex = pd.date_range("20130101", periods = 6) print(datetimeIndex) """ DatetimeIndex(['2013-01-01', '2013-01-02', '2013-01-03', '2013-01-04', '2013-01-05', '2013-01-06'], dtype='datetime64[ns]', freq='D') """ |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip install pandas 명령을
더 읽기
■ Series 클래스의 생성자를 사용해 Series 객체를 만드는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
import pandas as pd import numpy as np series = pd.Series([1, 3, 5, np.nan, 6, 8]) print(series) """ 0 1.0 1 3.0 2 5.0 3 NaN 4 6.0 5 8.0 dtype: float64 """ |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip install pandas 명령을 실행했다.
■ DataFrame 클래스의 to_stata 메소드를 사용해 STATA 데이타 파일을 생성하는 방법을 보여준다. ▶ main.py
|
|
import pandas as pd dataFrame = pd.read_stata("data1.dta") dataFrame.to_stata("tips2.dta") |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip install pandas
더 읽기
■ read_stata 함수를 사용해 STATA 데이터 파일을 로드하는 방법을 보여준다. ▶ main.py
|
|
import pandas as pd dataFrame = pd.read_stata("data.dta") |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip install pandas 명령을 실행했다.
■ DataFrameGroupBy 클래스의 transform 메소드를 사용해 그룹별 데이터를 집계하는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
import pandas as pd import numpy as np dataFrame1 = pd.DataFrame({"key" : ["A", "B", "C", "D"], "value" : np.random.randn(4)}) dataFrame2 = pd.DataFrame({"key" : ["B", "D", "D", "E"], "value" : np.random.randn(4)}) dataFrame3 = dataFrame1.merge(dataFrame2, on = ["key"], how = "outer") dataFrameGroupBy = dataFrame3.groupby("key") series1 = dataFrameGroupBy.transform("mean" )["value_x"] series2 = dataFrameGroupBy.transform("mean" )["value_y"] series3 = dataFrameGroupBy.transform("sum" )["value_x"] series4 = dataFrameGroupBy.transform("sum" )["value_y"] series5 = dataFrameGroupBy.transform("count")["value_x"] series6 = dataFrameGroupBy.transform("count")["value_y"] dataFrame3 = pd.DataFrame( { 'mean_x' : series1, 'mean_y' : series2, 'sum_x' : series3, 'sum_y' : series4, 'count_x' : series5, 'count_y' : series6 } ) print(dataFrame3) """ mean_x mean_y sum_x sum_y count_x count_y 0 1.054826 NaN 1.054826 0.000000 1 0 1 0.780643 0.105718 0.780643 0.105718 1 1 2 -0.780831 NaN -0.780831 0.000000 1 0 3 -0.709413 -1.636002 -1.418825 -3.272004 2 2 4 -0.709413 -1.636002 -1.418825 -3.272004 2 2 5 NaN 1.348015 0.000000 1.348015 0 1 """ |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip install pandas 명령을
더 읽기
■ DataFrameGroupBy 클래스의 agg 메소드를 사용해 그룹 데이터의 평균/합계/수를 집계하는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
import pandas as pd import numpy as np dataFrame1 = pd.DataFrame({"key" : ["A", "B", "C", "D"], "value" : np.random.randn(4)}) dataFrame2 = pd.DataFrame({"key" : ["B", "D", "D", "E"], "value" : np.random.randn(4)}) dataFrame3 = dataFrame1.merge(dataFrame2, on = ["key"], how = "outer") dataFrameGroupBy = dataFrame3.groupby("key") dataFrame4 = dataFrameGroupBy.agg(["mean", "sum", "count"]) print(dataFrame4) """ value_x value_y mean sum count mean sum count key A 0.052300 0.052300 1 NaN 0.000000 0 B -0.128339 -0.128339 1 0.874078 0.874078 1 C 0.868257 0.868257 1 NaN 0.000000 0 D 0.095844 0.191688 2 -0.356354 -0.712709 2 E NaN 0.000000 0 0.843800 0.843800 1 """ |
▶ requirements.txt
|
|
numpy==2.1.2 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip install pandas
더 읽기
■ DataFrameGroupBy 클래스의 transform 메소드에서 커스텀 집계 함수를 설정하는 방법을 보여준다. ▶ main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
import pandas as pd import numpy as np dataFrame1 = pd.DataFrame({"key" : ["A", "B", "C", "D"], "value" : np.random.randn(4)}) dataFrame2 = pd.DataFrame({"key" : ["B", "D", "D", "E"], "value" : np.random.randn(4)}) dataFrame3 = dataFrame1.merge(dataFrame2, on = ["key"], how = "outer") dataFrameGroupBy = dataFrame3.groupby("key") def customFunction(x): return x - x.mean() dataFrame4 = dataFrameGroupBy.transform(customFunction) print(dataFrame4) """ value_x value_y 0 0.0 NaN 1 0.0 0.000000 2 0.0 NaN 3 0.0 0.993518 4 0.0 -0.993518 5 NaN 0.000000 """ |
▶ requirements.txt
|
|
numpy==2.1.3 pandas==2.2.3 python-dateutil==2.9.0.post0 pytz==2024.2 six==1.16.0 tzdata==2024.2 |
※ pip install pandas 명령을
더 읽기